Meta-Model¶
Analysis of scientific models is typically a manual process in which specific simulation scenarios are formulated in code, executed, and the results evaluated. In EMMAA, models will be semantically annotated with concepts allowing scientific queries to be automatically formulated and executed. The core component of this process will be a meta-model for associating the necessary metadata with specific model elements.
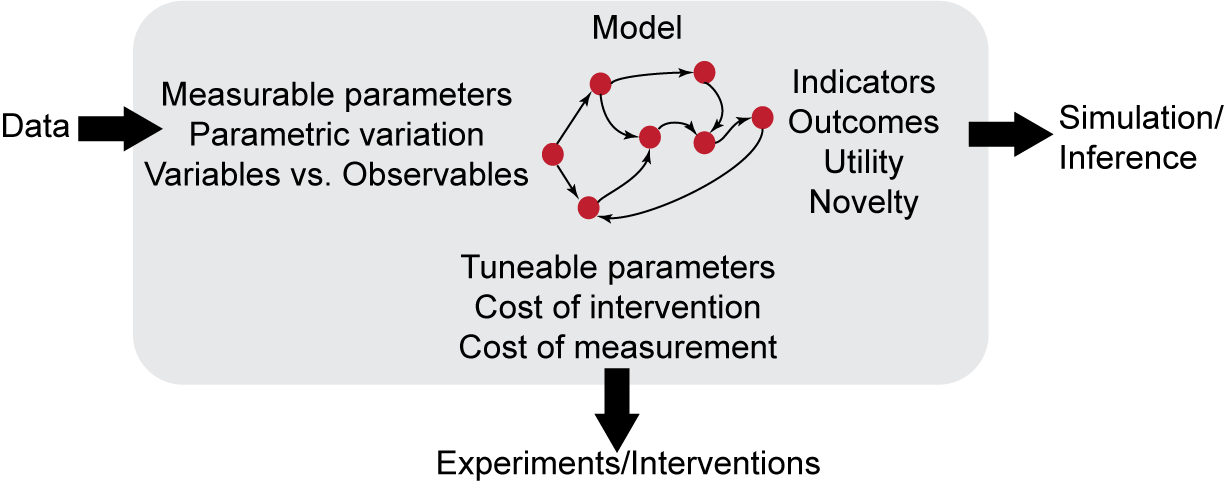
As shown in the figure above, the EMMAA meta-model will allow the annotation of:
relevant entities (e.g., specific genes or biological processes)
relations/processes (e.g., phosphorylation, activation)
quantities in model-relevant data (e.g., measured values associated with specific model parameters)
features of model parameters and observables relevant to subsequent experimental follow-up (e.g.,for example whether a parameter can be experimentally altered or whether measurement of a particular observable is cost-effective)
higher-level scientific aspects associated with model variables and outcomes, such as the utility associated with particular model states (e.g., decreased cell proliferation)
The EMMAA meta-model allows model elements encoded in different formalisms to be associated with the concepts necessary for automated analysis in EMMAA. For example, a protein initial condition parameter from an executable PySB model could be linked to the EMMAA concepts for a parameter that is naturally varying, non-perturbable, and experimentally measurable.
While several of these concepts have not been previously implemented in existing ontologies for semantic annotations of biological models, we will aim to reuse terms and concepts from ontologies developed by the COMBINE community where appropriate. These may include:
MIRIAM (Minimimal Information Required In the Annotation of Models)
SED-ML (Simulation Experiment Description Markup Language)
SBO (Systems Biology Ontology)
KISAO (Kinetic Simulation Algorithm Ontology)
MAMO (the Mathematical Modeling Ontology)
SBRML (Systems Biology Results Markup Language)
TEDDY (TErminology for the Description of DYnamics)
Initial specification of annotation guidelines¶
The meta-model will be implemented as a specification that can be implemented in different ways depending on the model type; in this way it will resemble the MIRIAM standard, which is not itself a terminology but rather a set of guidelines for using of (subject, predicate, object) triples to link essential model features to semantic concepts.
The EMMAA meta-model establishes several specific concepts and annotation guidelines aimed at automating high-level scientific queries. In particular, the initial specification for model annotation in EMMAA includes the following requirements to support basic simulation and analysis tasks:
Model entities (e.g., variables in an ODE model, nodes in a network model) must be linked to identifiers in external ontologies.
Entity states (e.g., phosphorylated, mutated, active or inactive proteins) should be identified semantically using an external ontology or controlled vocabulary.
Model processes (e.g., reactions in an ODE model, edges in a network model) must be linked to a piece of knowledge including provenance and evidence. In our initial implementation, this will be accomplished using the has_indra_stmt relation which will link back to an underlying INDRA statement.
Entities participating in processes should be identified with their role (e.g subject or object) for directional analysis.
(Optional): if it is not already implicit in the modeling formalism, the model process can be annotated with the sign of the process on its participants (i.e., positive or negative regulation).
EMMAA currently supports “does X…” queries for PySB models¶
Annotating a model using the five types of information above supports high-level queries such as: “Does treatment with drug X cause an increase in the phosphorylation of protein Y?” Answering this yes-or-no query makes use of model annotations in the following way:
Entities in the model representing drug X are identified (#1, above).
Entities in the model representing phosphorylated Y are identified (#1 and 2).
Processes with drug X as the subject are identified, as are processes with phosphorylated Y as the object (#4, above).
The effect of the drug X entities/processes on the phosphorylated protein Y entities/processes are determined using a model-specific analytical procedure, making use of sign information if necessary (#5).
The analysis results are linked back to the knowledge model via has_indra_stmt annotations (#3).
We currently have an end-to-end implementation that uses model annotations to answer these types of queries for a single model type: executable dynamical models implemented in PySB. Model annotations are generated as part of the PySB model assembly process in INDRA; for instance see the PySB Assembler code here for an example of how the PySB Annotation class is used to associate entities with their role (subject/object) in a process (#4).
To answer a “does” query like the one specified above, the ModelChecker makes use of these annotations to search for a path through the model’s influence map with the appropriate sign.
These types of queries can currently be used to formulate model tests using
the StatementCheckingTest (emmaa.model_tests.StatementCheckingTest),
and triggered automatically upon every model update using the testing pipeline
described in Model Testing and Analysis.
Annotations required for “what if” queries¶
As opposed to a “does X…” query like the example above, which are used to determine the connectivity and sign of causal paths in the model at baseline, a “what if” query indicates a perturbation and involves an open-ended response. For example, consider the following queries:
“What happens to protein X if I knock out protein Y?”
“What happens to protein X if I double the amount of drug Y?”
“What happens to protein X if I decrease its affinity to drug Y?”
Addressing these queries in general requires designating a model control condition (e.g., a specific initial state or steady state) that is perturbed by the manipulation of model structure or parameters. This requires the following model features to be identified by additional annotations:
Model parameters governing entity amounts
Effect of model parameters on the strength of interaction between entities (for example, the forward and reverse rates of a binding interaction both affect the affinity of the interaction, but in opposite ways).
Annotations required for open-ended “relevance” queries¶
Finally, we aim to enable the automation of analysis procedures that are not based on explicit queries but rather aimed at identifying model characteristics that have scientific relevance and value. An example would be to “notify me of mechanistic findings therapeutically relevant to pancreatic cancer.” This type of query requires additional annotations on the higher-level biological processes associated with model entities and their scientific relevance. We aim to implement the following additional three annotations for this purpose:
Biological processes or phenotypes associated with specific model entities, and their sign (e.g., phosphorylated MAPK1 is positively associated with cell proliferation in pancreatic cancer).
A value criterion associated the biological process (e.g., it is therapeutically desirable to increase cancer cell apoptosis, and decrease cancer cell proliferation).
Entity types that represent actionable perturbations. For example, it may be of greater interest to identify a chemical perturbation that yields a desirable affect than a genetic perturbation, because (at least present) chemical perturbations are more experimentally and therapeutically tractable.
These ten annotation types represent the initial set for the EMMAA cancer models.